在互聯(lián)網(wǎng)技術(shù)高速發(fā)展的今天,隨著用戶規(guī)模和數(shù)據(jù)量的爆炸式增長,傳統(tǒng)的單一數(shù)據(jù)庫架構(gòu)往往難以支撐海量數(shù)據(jù)存儲(chǔ)與高并發(fā)訪問的壓力。分庫分表作為一種核心的數(shù)據(jù)庫水平擴(kuò)展方案,已成為構(gòu)建高性能、高可用互聯(lián)網(wǎng)系統(tǒng)的關(guān)鍵技術(shù)手段。本文旨在匯總互聯(lián)網(wǎng)技術(shù)架構(gòu)中幾種主流的分庫分表方案,分析其核心思想、適用場景與優(yōu)缺點(diǎn),為技術(shù)選型提供參考。
一、 分庫分表的核心概念與目標(biāo)
分庫分表,本質(zhì)上是將原本存儲(chǔ)在單一數(shù)據(jù)庫(實(shí)例)中的單張數(shù)據(jù)表,按照特定規(guī)則拆分到多個(gè)數(shù)據(jù)庫(分庫)或多張數(shù)據(jù)表(分表)中。其主要目標(biāo)在于:
- 解決數(shù)據(jù)存儲(chǔ)瓶頸:突破單機(jī)磁盤容量限制,支持海量數(shù)據(jù)存儲(chǔ)。
- 提升系統(tǒng)性能:分散讀寫壓力,降低單庫單表的鎖競爭與I/O負(fù)載,提高并發(fā)處理能力。
- 增強(qiáng)系統(tǒng)可用性:通過數(shù)據(jù)冗余和分布,避免單點(diǎn)故障,提升系統(tǒng)整體可用性與容災(zāi)能力。
二、 常用分庫分表方案匯總
分庫分表的實(shí)現(xiàn)方式多樣,可根據(jù)業(yè)務(wù)特點(diǎn)、數(shù)據(jù)特性和擴(kuò)展需求進(jìn)行選擇和組合。
1. 水平拆分
這是最主流的拆分方式,即按行拆分,將一張表中的不同行記錄分散到不同的庫或表中。所有拆分后的表結(jié)構(gòu)完全一致。
- 按范圍分片:根據(jù)某個(gè)字段(如用戶ID、訂單創(chuàng)建時(shí)間)的范圍進(jìn)行劃分。例如,將用戶ID在1-100萬的記錄存入DB1,100萬-200萬的存入DB2。優(yōu)點(diǎn)是易于理解和擴(kuò)展,但可能存在數(shù)據(jù)分布不均(熱點(diǎn)數(shù)據(jù))的問題。
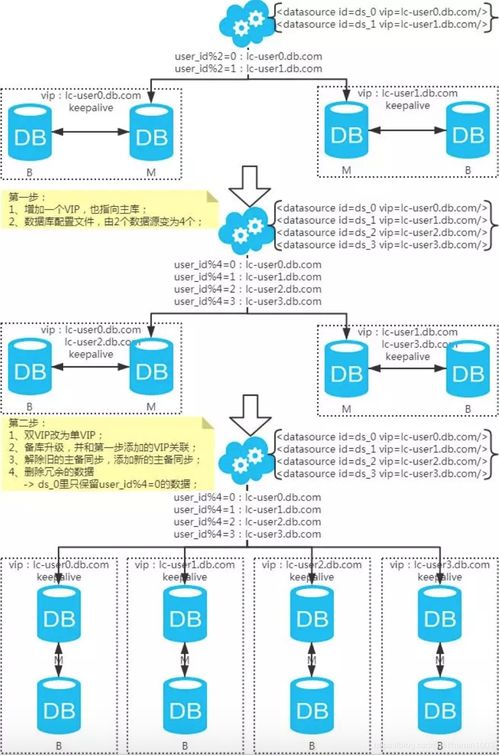
- 哈希取模分片:根據(jù)某個(gè)字段(通常是主鍵或業(yè)務(wù)關(guān)鍵字段)的哈希值進(jìn)行取模運(yùn)算,根據(jù)結(jié)果決定數(shù)據(jù)路由到哪個(gè)庫或表。例如,
user_id % 4。優(yōu)點(diǎn)是數(shù)據(jù)分布相對均勻,但后期擴(kuò)容(如從4庫擴(kuò)到5庫)時(shí),數(shù)據(jù)遷移和重新分片的工作量巨大,影響線上服務(wù)。 - 一致性哈希分片:為解決哈希取模擴(kuò)容難題而引入。通過構(gòu)建一個(gè)哈希環(huán),將數(shù)據(jù)節(jié)點(diǎn)和數(shù)據(jù)鍵值映射到環(huán)上,按順時(shí)針方向?qū)ふ易罱臄?shù)據(jù)節(jié)點(diǎn)。在節(jié)點(diǎn)增減時(shí),僅需遷移環(huán)上相鄰節(jié)點(diǎn)的部分?jǐn)?shù)據(jù),大大減少了數(shù)據(jù)遷移量。
2. 垂直拆分
即按列拆分,將一張寬表中的不同字段拆分到不同的庫或表中。通常根據(jù)業(yè)務(wù)模塊或字段訪問頻次進(jìn)行劃分。
- 垂直分庫:根據(jù)業(yè)務(wù)模塊將不同表拆分到不同數(shù)據(jù)庫中。例如,將用戶相關(guān)表放入用戶庫,訂單相關(guān)表放入訂單庫。這有助于業(yè)務(wù)解耦和數(shù)據(jù)庫專庫專用。
- 垂直分表:將一張表中不常用或占用空間大的字段拆分出去,形成主表與擴(kuò)展表。例如,將用戶基本信息(姓名、電話)放在主表,將用戶詳情(個(gè)人簡介、頭像地址)放在擴(kuò)展表。這有助于提升核心字段的查詢效率。
3. 混合拆分策略
在實(shí)際大型系統(tǒng)中,通常會(huì)結(jié)合使用垂直拆分和水平拆分。先進(jìn)行垂直拆分,將不同業(yè)務(wù)域分離;再對業(yè)務(wù)域內(nèi)數(shù)據(jù)量巨大的單表進(jìn)行水平拆分,形成“垂直分庫+水平分表”的經(jīng)典架構(gòu)。
4. 基于中間件的解決方案
為了降低分庫分表后帶來的應(yīng)用層復(fù)雜度(如SQL解析、路由、結(jié)果合并、事務(wù)管理等),業(yè)界涌現(xiàn)了許多成熟的數(shù)據(jù)庫中間件。
- 客戶端模式:以ShardingSphere-JDBC為代表,將分片邏輯封裝在應(yīng)用端的JDBC驅(qū)動(dòng)中,以jar包形式提供,對應(yīng)用透明性較低,但性能損耗小,架構(gòu)簡單。
- 代理模式:以ShardingSphere-Proxy、MyCat為代表,獨(dú)立部署一個(gè)代理服務(wù),應(yīng)用像連接單庫一樣連接代理,由代理完成所有分片和路由工作。對應(yīng)用透明性高,但多一層網(wǎng)絡(luò)跳轉(zhuǎn),存在性能損耗和單點(diǎn)風(fēng)險(xiǎn)。
- 云原生方案:各大云服務(wù)商(如AWS Aurora、阿里云PolarDB、騰訊云TDSQL)也提供了集成了自動(dòng)分片、彈性擴(kuò)展、分布式事務(wù)等能力的數(shù)據(jù)庫服務(wù),開箱即用,但通常與特定云平臺(tái)綁定。
三、 分庫分表的挑戰(zhàn)與應(yīng)對
實(shí)施分庫分表在帶來收益的也引入了新的挑戰(zhàn):
- 分布式事務(wù):數(shù)據(jù)分布在多個(gè)庫中,保證跨庫事務(wù)的ACID特性變得復(fù)雜。可采用最終一致性方案(如基于消息隊(duì)列)、分布式事務(wù)框架(如Seata)或使用數(shù)據(jù)庫本身支持的分布式事務(wù)(如XA)。
- 跨庫/表查詢與聚合:涉及多個(gè)分片的JOIN、ORDER BY、GROUP BY等操作變得困難。應(yīng)對策略包括:業(yè)務(wù)上避免跨分片復(fù)雜查詢、設(shè)計(jì)冗余字段或?qū)挶怼⒂芍虚g件進(jìn)行數(shù)據(jù)聚合、或使用OLAP分析型數(shù)據(jù)庫承接復(fù)雜查詢。
- 全局唯一ID生成:單庫自增ID在分布式環(huán)境下會(huì)重復(fù)。需引入分布式ID生成方案,如雪花算法(Snowflake)、UUID、數(shù)據(jù)庫號段模式等。
- 數(shù)據(jù)遷移與擴(kuò)容:在線平滑擴(kuò)容是關(guān)鍵難題。一致性哈希、雙寫遷移、在線數(shù)據(jù)重分布工具等是常見的解決方案。
四、
分庫分表是互聯(lián)網(wǎng)系統(tǒng)應(yīng)對海量數(shù)據(jù)與高并發(fā)的有效路徑,但并非銀彈。技術(shù)選型時(shí),應(yīng)首先評估業(yè)務(wù)現(xiàn)狀與未來規(guī)劃,優(yōu)先考慮通過緩存、讀寫分離、SQL優(yōu)化、硬件升級等手段提升性能。當(dāng)單庫單表確實(shí)成為瓶頸時(shí),再謹(jǐn)慎選擇合適的分片鍵與拆分方案,并充分評估其帶來的復(fù)雜性。結(jié)合成熟的中間件或云服務(wù),可以更高效、更穩(wěn)定地構(gòu)建分布式數(shù)據(jù)存儲(chǔ)層,為業(yè)務(wù)的持續(xù)快速發(fā)展奠定堅(jiān)實(shí)的技術(shù)基礎(chǔ)。